Problem
This is a three part feature request
This is a great package and I really want it to succeed but there are some really irritating issues that need features to resolve them.
1: More granular control over what gets generated
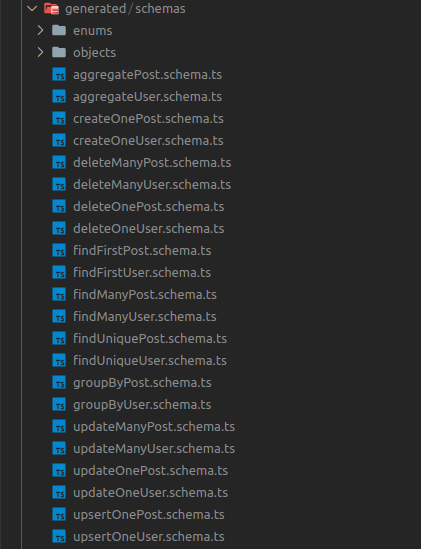
I posted this issue on your prisma tRPC generator but it seems more relevant here and I'm going to add a bit more detail here on why it's needed and a more detailed solution. A major feature that's lacking from this package is the lack of granularity with what gets generated. For example, our app has about 8 different routes. Only 4 need full CRUD functionality, the rest are mainly for reading, and creation, deletion and update are manually handled by employees using prisma studio. The number of schemas and objects generated by this generator is ludicrous, most simply won't be needed for most use cases. This also makes integrating the codegen process into the development process slower, as you need to manually remove the unnecessary files or manually select all of the useful while leaving the bloat, both of which require with developer time or code to maintain. You should just be able to get what you actually need to use in as close to the way you need to use it as possible. Having more granular control is important to increase the adoption of this package as it will mean people can use it more flexible and generate only what they need for their specific use case
2: Excludeable fields
On this note, some fields are not relevant to the Prisma client and don't need to be type checked. For example, we may have an optional field on the backend for administrative purposes that is manually inputted and checked by our employees and is never going to be submitted by Prisma client, so it just gets in the way being there. This isn't that much of an issue for the prisma client but it is for using tRPC with Zod, and this is one of the biggest issues. The generated schema becomes practically useless as it can't be used to automatically validate incoming requests to tRPC because it contains fields that are never going to be submitted by the client. You have to either then manually edit and cut fields from the schema, which detracts from the usefulness of the codegen in the first place, or add a bunch of omits to the object in the tRPC procedure input, which again isn't ideal, especially if the model has a relation and hence is a z.ZodSchema not a z.object so you can't use omit.
Having control over what fields get generated is crucial for allowing the generation of useful Zod schema. Having complete Prisma schema for every Prisma model and client action is relatively useless if you can't then use those to validate the input your client will actually be sending to your tRPC endpoint. Just one more example here as to why it's necessary, for example, our user may send information like their name, email, address, etc. but will not send things like their user type, which is conditionally added at the API level. However, the generated schema will just fail the request as not being valid because it doesn't contain the user type, which can't be conditional as it is needed in later steps. This leads nicely onto my next point
3: Multiple exported schemas per Model
Given that the creator of this package also manages various tRPC, Zod and Prisma related packages, it seems worthwhile to point out that the main schemas generated by this package won't be that useful for most client's inputs coming into tRPC. Not everyone will be sending their data exactly as it will be stored in the database in their request from the client, so as I stated above, these schemas are not hugely useful or need heavy editing. One potential remedy for this is adding the option to generate two schemas for specific Prisma models, one for Prisma client validation and one for tRPC input validation. I'll explain more below
Suggested solution
Adding a config file
I'm not particularly well versed on the Prisma schema syntax and how it interacts with generators. In an ideal world something like the below would be great
{
modelName: {
createOne: true,
createMany: false,
findUnique: true,
....
}
}
However, just at a glance I doubt prisma's schema will allow json objects. I'm not sure if you can even do nesting,
something like a YAML like syntax could work if that's possible like
modelName:
createdOne: true
createMany: false
findUnique: true
But, these likely both won't work. Perhaps, one way around this might be to have a separate config file that that is assigned in the prisma.schema and passed to the actual generator file
generator zod {
provider = "prisma-zod-generator"
output = "./generated-zod-schemas"
config = "./zod-generator.json" // zod generator config path goes here
isGenerateSelect = true
isGenerateInclude = true
}
I think this is likely the root of solving all three issues. You pass in your input as a json object, or maybe as yaml, and this is used to conditional transform your code into the correct output. For example,
{
"models": {
"User": {
"generate": true, // potentially redundant
"prisma": {
"removeFields": ["createdAt"] // those included are removed
"includeMethods": ["createdOne"] // only those included are generated
},
"trpc": {
"removeFields": ["createdAt", "userType"] // those included are removed
}
}
"Account": {
"generate": false // prevents schema model from being generated
}
...moreModels
},
...additionalOptions
}
This is by no means perfect and there's a lot of room to improve the syntax. One potential compliant is that this separates the logic from the prisma.schema, which personally I prefer, as after using zod-prisma, all the comments clog up the file pretty fast. This obviously doesn't include anything about how this would actually be done by the generator, which I imagine is the actual hard part but hopefully this is a helpful start
Additional context
If you can provide some guidance, I'd be happy to assist with some of this
enhancement














![[prisma v2.x] Types for createOne / updateOne may be incomplete](https://avatars.githubusercontent.com/u/3766777?v=4)











 26 Dec 24, 2022
26 Dec 24, 2022
 17 Dec 17, 2022
17 Dec 17, 2022
 339 Dec 28, 2022
339 Dec 28, 2022
 197 Jan 5, 2023
197 Jan 5, 2023
 39 Dec 2, 2022
39 Dec 2, 2022
 9 Dec 24, 2022
9 Dec 24, 2022
 184 Dec 21, 2022
184 Dec 21, 2022
 21 Dec 28, 2022
21 Dec 28, 2022
 6 Aug 17, 2022
6 Aug 17, 2022
 2 Oct 12, 2022
2 Oct 12, 2022
 344 Dec 29, 2022
344 Dec 29, 2022
 104 Jan 4, 2023
104 Jan 4, 2023
 70 Dec 23, 2022
70 Dec 23, 2022
 172 Dec 22, 2022
172 Dec 22, 2022
 16 Dec 6, 2022
16 Dec 6, 2022
 60 Dec 28, 2022
60 Dec 28, 2022